![]() Import From File
Import From File
As I did years ago, many collectors still use a spreadsheet program such as Microsoft Excel for entry of their collection information. While definitely functional, a standard spreadsheet is a bit ackward to include images, as well as difficult to export the information into a variety of formats around those images. Since my primary goal with CanDB is the production of digital pictorials, CanDB provides a way for collectors to easily migrate from existing Excel content to CanDB using “File -> Import From File”.
In order to support CanDB import from Excel
there were essentially two options. One, have collectors rename and possibly
reformat their spreadsheet columns and data into CanDB terms, or two, have
CanDB be able to read the collector’s spreadsheet data “as is” and CanDB do the
work of parsing and mapping spreadsheet content. I know for myself I would prefer
to do as little as possible to import my data into a different program, so
while definitely harder to program CanDB, option two was the only practical
choice!
Step 1: Save Excel as tab delimited file
To import from Excel into CanDB, you must first save your Excel content to a tab delimited text file. From within Excel, choose “File -> Save As”, and for “Save as type” choose the option “Text (Tab delimited) (*.txt)”. The following is an example from Excel 2010. Note to other programmers, any tab separated content will work, not just Excel.
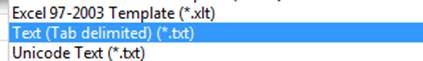
Step 2: CanDB “File -> Import From File”
Within CanDB, chose the menu item “File -> Import From File” which will open the following dialog. Note: You can only import into an empty project. If your project has at least one brewery or item defined, the Import From File menu item will be grayed out.
While the following dialog may look intimidating at first, remember the goal is to require you to essentially change nothing in your spreadsheet, but instead CanDB be able to determine how to map your existing data into CanDB terms. As such, CanDB needs some information for how to map your column data, as well as possible delimiters if your columns have more than one piece of information in the same cell. For example, collectors may have a column called “Name” which might have values such as “Altes Sportsman Ale – 30,000 Archers” where the “-“ (dash) character is used as delimiter between Name and Extra Information.
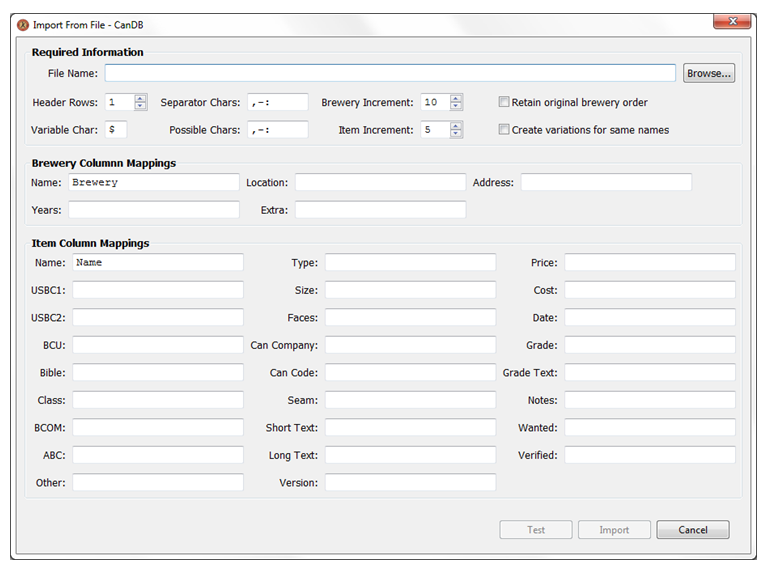
The “Required” information section is described below. Hopefully you will be able to simply use most of the CanDB import defaults.
|
Property |
Description |
|
File Name |
Of course CanDB will need to know the file name of your tab delimited text file. Either type the full path name into the text box or click the “Browse…” button to use a FileChooser to select the tabbed text file. |
|
Header Rows |
Number of rows at the top of your spreadsheet with “column names”. For example, your spreadsheet may have column names of “Name”, “Brewery”, “USBC”, “Cost”, “Notes”, “Grade”, etc. For most spreadsheets this will be just a single row (value “1”) but multiple rows are possible as shown in a later example. |
|
Separator Chars |
This is the set of delimiter characters breaking a single cell entry into multiple “variables”. Your spreadsheet might have a single column with “City, State”, or a single column with “Name – Extra Info”. By allowing user control over these separator/delimiter characters, CanDB parsing can be tailored per your spreadsheet conventions. |
|
Possible Chars |
Say you used the “-“ (dash) character as separator in your Name column, and might have something like “Altes Sportsman Ale – 30,000 Archers”. If you define “-“ or "," as a separator character CanDB can easily split this column value. However, now consider you have the name “Mann-Chester”. Humans can easily notice the “-“ in this case is part of the can’s name, not really a delimiter. Unfortunately, CanDB doesn’t include any AI programming and doesn’t know this. As such, the configuration “Possible Chars” indicates a given character is only a delimiter if the character is preceded by a space/blank. If “-“ is included in the “Possible Chars”, for Mann-Chester it is NOT a delimiter, for “Ale – 30,000” it is a delimiter. |
|
Brewery Increment |
How to number the generated CanDB breweries. Recommendation is something like 5 or 10, not consecutively numbered 1..N. While you can always re-number, start with the default. |
|
Item Increment |
How to number the generated CanDB items within a given brewery. Same as above, recommendation is something like 5 or 10. |
|
Retain Original Brewery Order |
After the file is fully imported, by default CanDB will sort the breweries alphabetically before assigning reference numbers. If this option is checked “true”, no sorting will be performed, keeping the order exactly as a brewery was discovered from the spreadsheet. There is no CanDB sorting of the items since assumption you already have them in order you prefer (Excel makes it very easy to sort rows). |
|
Create Variations for Same Name |
CanDB stores items in folders based on short name, as such, does not allow multiple items to have the same name. If you have two rows with the same item name, CanDB will either add digits to end of the names (the default) or if you check this box “true”, same named items will be added as variations to the first found base item. Within my CSS and MBC projects I have numerous variations that differ only by canning company, code, seam, lid, etc. |
|
Variable Char |
Consider you have a column named “Notes” with your convention to have single data cell with “Grade, Grade Information”, comma delimited. CanDB stores these as two separate properties. If you indicate “,” as a delimiter, when your Notes column is parsed, the cell value will be split into “Grade” and “Grade Information”, values referenced by variables $1 and $2 respectively. I doubt you have a need to change this character. |
Step 3: Define mapping of your column names to CanDB properties
In the most simplest case, you just need to enter your column names into the corresponding CanDB property name boxes. For example, your column named “A” maps to CanDB “Name”, “B” maps to “Cost”, and “C” maps to “Date”. When CanDB processes your file, it parses the indicated number of header rows (default of one row) attempting to find your specified column names, which then map to CanDB properties, along with rules how to parse/delimit the given cell.
If a mapping starts with one of your delimiter characters, CanDB will parse that cell and split any value into variables based on the delimiter. For example, if you define a mapping of “-Name” (leading dash) this indicates your column Name should be split around the “-“ delimiter into variables $1, $2, $3, etc for each delimited value. In many example spreadsheets the mapping “-Name $1” would be appropriate to extract the name, putting the variables $2, $3 etc into other CanDB properties.
Some notes:
· Your spreadsheet must have a column mapping to “Brewery” and a column mapping to “Name”. Without these two cell values CanDB will have no idea how to create necessary brewery or item objects. If your spreadsheet does not have a Brewery column, you will need to at least add one at the far most column with all cells the same text value.|
· Your spreadsheet can’t have more than one column with exactly the same name. For example, not allowed to have two columns named “Name”.
· If after viewing the following examples and/or some experimentation you don’t get the import results you desire, please email me a copy of your spreadsheet with header row(s) and 5-6 rows of sample data values, and I will email back a screen shot of CanDB configuration to import your specific format.
Step 4: Click the “Test” button
Before importing data, click “Test” which will cause CanDB to parse your tab delimited text file, validate mapping names, report number of breweries and items found, and show CanDB determined column mapping. No actual data will be imported into your project. You may need to iterate a few times before you get your configuration exactly as you would like.
Step 5: Click the “Import” button
Assuming you have no errors in your configuration, CanDB will parse your tab delimited text file and import all configured content into CanDB properties. Simply view the imported CanDB data, with all imported data automatically saved under the current project. While I have did a fair amount of testing this feature, if you don’t think CanDB is doing the correct processing per configuration, or rare chance an exception is thrown, please contact me and I will attempt to help define proper configuration or if necessary make CanDB bug fixes.
Real examples
Click on the following to view three real collector spreadsheets used for CanDB testing.